
Moved to a new host, and I decided to drop the old "Mondrian" theme. I haven't restored the Wiki half of the site, so some pages are gone for now.
Two years since my last marathon
Edmonton 2012 was my last full marathon. I was worried that if I stopped racing, that I would stop running, but that hasn't happened. In fact, I run more often than I did when I was training for the big races. Back then, I would adhere to a strict training schedule, but now I just go out and run every day!
Wild Orchids

Lady Slippers near Prince George, BC.
A rare find… Lady Slippers. The sepals have dried up, but the slippers themselves are in fine shape. This plant was part of a large, healthy colony near a ditch. I couldn't resist taking a photograph. Like all wild orchids, these are protected by law.
On the same trip, I saw 14 bears by the highway… unlike the orchids, the bears aren't exactly rare so I didn't stop to take any pictures of them.
Fool me twice
This was my second time running the Fool's on the Sunshine Coast. It is a challenging run, with several steep downhill stretches that turn one's legs into jelly. I finished in 1:25:59 which is almost identical to three years ago (1:26:03). Lots of great runners in this race, the top masters (Kevin O'Connor) ran it in 1:09:12, which they said was a national masters record. This was also an opportunity to enjoy some good grub with the family, who live around these parts.
NIFTI plain and simple
I work with medical images, and that means a lot of work with medical image file formats. DICOM is the big one, since it is the industry standard, but I've also spent a lot of time with MINC and NIFTI, which are central to research within the clinical neurosciences. This post regards NIFTI, which is both the simplest format of the three, and at times the most vexing. NIFTI is a fixed header format, so each piece of information resides at a specific byte offset within the file. Writing code to read or write such a file should be easy, in fact that is exactly why it uses a fixed header. However, the use of a fixed header causes problems with the evolution of the format.
When it came time to make a "NIFTI-2" specification, it was necessary to create a completely new header structure that was incompatible with the old one. This means that old NIFTI-1 software cannot read the new files, and new NIFTI software has to essentially contain two decoders: one for NIFTI-1, and one for NIFTI-2. Also, the people who wrote the NIFTI-2 header goofed: the header contains elements that must be 8-byte aligned (i.e. 64-bit aligned), but the header itself is 540 bytes long, which is not divisible by 8. This means that, whenever a 64-bit compiler creates a nifti_2_header struct in memory, it allocates an extra 4 bytes of padding. If one calls sizeof(nifti_2_header) on a 64-bit machine, it returns 544 instead of 540. On my first attempt to read a NIFTI-2 file, I used read(sizeof(nifti_2_header)) and ended up reading 4 bytes too many! The silliest part of this is that the last element of nifti_2_header is just a 15-byte space reserved for future expansion, so they could have reserved 19 bytes instead and avoided this issue altogether! As a "solution", the official NIFTI-2 header uses the dangerous "#pragma pack(1)" setting to force the compiler to forgo alignment in favor of making sizeof() return the desired value.
Even before NIFTI-2 arrived, there were problems because the NIFTI-1 header was based on the old Analyze-7.5 header, but it had to "repurpose" several header fields in incompatible ways. This meant that, by avoiding these fields, people could write NIFTI files that could be read by software designed for Analyze-7.5 files. Conversely, it was altogether possible to write NIFTI files that were, essentially, corrupted Analyze-7.5 files. That is why fixed-header file formats are bad. Instead of simply obsoleting old header fields and adding new ones, any significant evolution of the format requires changing the header in incompatible ways.
My Own DICOM
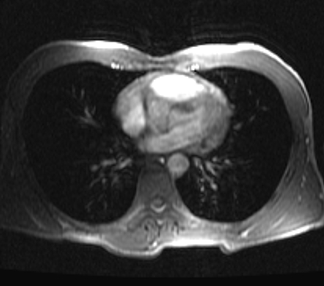
DICOM images have been a big part of my job for over a decade, but until recently I swore that I would never write my own programming library for reading DICOM files. Not when there were mature, free DICOM libraries that I could use instead. But I needed something that would integrate seamlessly with the image analysis software that we are writing, which is all based on VTK. Hence, the genesis of vtk-dicom, a DICOM library specifically for VTK.
There are a few features that I am especially proud of:
- It can handle files with over 4 dimensions (both read and write).
- It works with the new "enhanced" multi-frame DICOM files.
- DICOM scans are managed as full series, rather than one image at a time.
- The meta data is stored in hash table with a very compact interface.
- The dictionary is built as a static hash table right in the code.
- Both the reader and write use an 8k buffer for efficient IO operations.
Stampede Road Race Number 3
Another half-marathon, this one in 1:25:16. Pace was 4:02 per km, I must be slipping! This is the first half where I didn't get a personal best. It was a great race overall, though, I placed 7th compared to two years ago when I placed eighth on this same course.
Getting source and build version with CMake.
These are some useful snippets of CMake code that I wrote today, so I thought that I's share them. They aren't CMake macros or functions or anything tidy like that, in fact I have them in the main CMakeLists.txt file of a project that I'm currently working on. The purpose of this code is to make it possible for my programs to print out full version information, so that even if I am working on some strange branch and haven't tagged a release, I'll always be able to check to see what source I used to produce that program:
myprogram --version
myprogram version 1.0.0 (master 1a8e6107, 16 Jun 2013, 17:50:26)
The first thing is to grab the git ref for the current head. I read ".git/HEAD" directly, rather than calling upon git itself (the "git describe" command is the more official way of getting such info, but it requires that at least one tag exists in the repository).
# Store the git hash of the current head
if(EXISTS "${PROJECT_SOURCE_DIR}/.git/HEAD")
file(READ "${PROJECT_SOURCE_DIR}/.git/HEAD"
PROJECT_SOURCE_VERSION)
if("${PROJECT_SOURCE_VERSION}" MATCHES "^ref:")
string(REGEX REPLACE "^ref: *([^ \n\r]*).*" "\\1"
PROJECT_GIT_REF "${PROJECT_SOURCE_VERSION}")
file(READ "${PROJECT_SOURCE_DIR}/.git/${PROJECT_GIT_REF}"
PROJECT_SOURCE_VERSION)
endif()
string(STRIP "${PROJECT_SOURCE_VERSION}"
PROJECT_SOURCE_VERSION)
endif()
Now that we have a PROJECT_SOURCE_VERSION variable set in CMake, the next thing is to grab the date and time and put them into PROJECT_BUILD_DATE and PROJECT_BUILD_TIME. This can be done easily on Linux and OS X by calling the "date" command, but Windows does not provide any way of formatting the output of it's date command so some string manipulation is required:
# Store the build date
if(WIN32)
execute_process(COMMAND "cmd" " /c date /t"
OUTPUT_VARIABLE DATE)
string(REGEX REPLACE "[^0-9]*(..).*" "\\1" MONTH "${DATE}")
set(MONTHS ""
"Jan" "Feb" "Mar" "Apr" "May" "Jun"
"Jul" "Aug" "Sep" "Oct" "Nov" "Dec")
list(GET MONTHS "${MONTH}" MONTH)
string(REGEX REPLACE "[^/]*/(..)/(....).*" "\\1 ${MONTH} \\2"
PROJECT_BUILD_DATE "${DATE}")
execute_process(COMMAND "cmd" " /c echo %TIME%"
OUTPUT_VARIABLE TIME)
string(REGEX REPLACE "[^0-9]*(..:..:..).*" "\\1"
PROJECT_BUILD_TIME "${TIME}")
else()
execute_process(COMMAND "date" "+%d %b %Y/%H:%M:%S"
OUTPUT_VARIABLE DATE_TIME)
string(REGEX REPLACE "([^/]*)/.*" "\\1"
PROJECT_BUILD_DATE "${DATE_TIME}")
string(REGEX REPLACE "[^/]*/([0-9:]*).*" "\\1"
PROJECT_BUILD_TIME "${DATE_TIME}")
endif()
This isn't quite everything: this only puts the needed information into CMake variables. It still necessary to add a project_config.h.in file that can be configured by CMake to make these values available to your C++ code:
/* Source and Build version info. */
#define PROJECT_GIT_REF "@PROJECT_GIT_REF@"
#define PROJECT_SOURCE_VERSION "@PROJECT_SOURCE_VERSION@"
#define PROJECT_BUILD_DATE "@PROJECT_BUILD_DATE@"
#define PROJECT_BUILD_TIME "@PROJECT_BUILD_TIME@"
Now your program has a set of string macros that it can print when the user asks what version of the source was used to build it.
Calgary Half
I ran a successful half today at the Calgary Marathon. Official time 1:23:56. It's quite the thing to look at your watch after an event like this and notice that it isn't even 8:30am yet. The best thing about my performance is that I had a great split… the 2nd half of the race took only 60s longer than the first half.
The Marathon Dilemma
I'm almost done training for the Calgary Marathon next week… for the half marathon, that is. For a half-marathon I train up to 25 km, but for a full, I train up to 50 km. There's a world of difference between these two distances. After a 25 km run, I can shower and get on with my day as if it was any other day. But anything over 30 km requires recovery time, and 50 km is way, way past 30 km. But these long, stamina-building runs are the key to getting a good finishing time and enjoying yourself on race day.
Here's the conundrum. I want to run full marathons, not halfs. During a full you always find one or two folks that match your pace and you get to know them a bit, but a half is too fast and too short for any chit-chat. Compared to a full marathon, a half is boring and not particularly challenging. Unfortunately, training for a full is decidedly less fun and takes a much greater toll on the body.
So should I cut back to just halfs? Hmm… I can always do another full marathon and then decide…